一个词法分析器的 Bug
写程序设计语言原理课的大作业(嗯……早做准备早放心)的时候遇到了一个奇怪的问题:本来应该只匹配不换行空白符的 WS token 竟然匹配了四个空格加一个 begin!这非常不对劲。
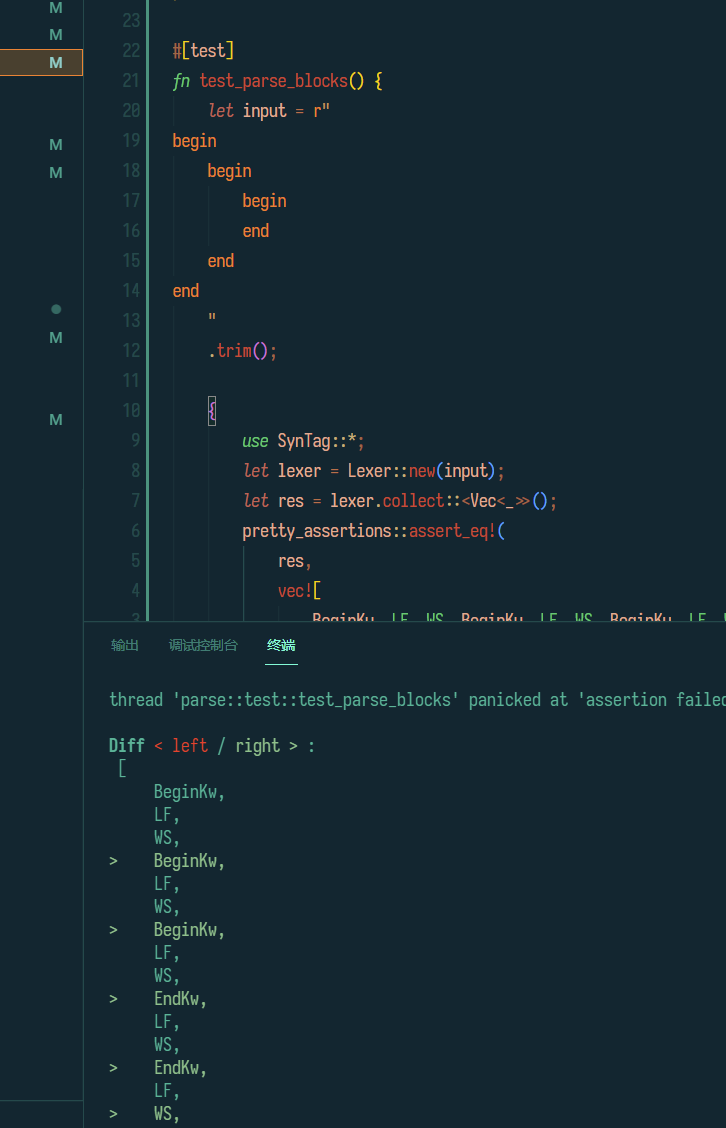
咱在这里用的 lexer 用的是 Logos 自动生成的(声明一下,Logos 还是非常好用的),于是咱去 issues 区找了一下,发现其他人也遇到了这个问题,比如
- #181 Bad matches for grammars that require backtracking(这个是主 issue)
- #200 Regex and token prefix causes error match
- #160 Strange behaviour when matching 'else' / 'else if'
等等。
问题
这些问题都有一个共性:在自动机的两个接受状态中间夹了一个不接受状态。我们可以用一个简单的例子说明这个问题:
假设我们现在有一个超级简单的 lexer,只接受两个 Token:
- TB ->
ac - TD ->
accc
其他所有输入都是错误。比如理想状态下 acacacccac 会被解析成 [TB, TB, TD, TB], acaccacaccc 会被解析成 [TB, TB, Error, TB, TD]。
我们希望用一个 DFA 来解决这个问题,于是我们写了个非常简单的自动机:
Start: S
Accepts: B (TB), D (TD)
-> S
S -[a]-> A
A -[c]-> B
B -[c]-> C
C -[c]-> D
然后当我们在接受状态且继续输入不能引起有效状态变化的时候,我们输出相应的 token 并退回到 S 状态,再接受刚刚的输入。
对于正确的输入没有什么问题,比如它可以完全正确地解析 acacacccac。
然后当我们输入 accd 的时候,它进行了 S -> A -> B -> C 的状态转换之后卡住了。
理想情况下,他应该回退一个状态,从 B 输出 Token TB acc ,然后输出一个 Error token d 。
但是这个作者没有实现 backtrack,于是它在 \万策尽きた/ 之后随便挑了一个 token 丢了出去。
当然在咱这个情况下,TB 对应的是空白符 Token WS -> [ \t]+, 然后 TD 对应的是(因为没有 contextual lexing 所以在任何时刻都会输出的)字符串插值中段 Token InterpolatedStringMiddle -> [^\r\n'"]\*$ 。不过 anyway,跟之前的简化模型一样,这两个接受一个共同的开头,然后其中一个匹配不了的时候另一个必须回溯才能匹配上。
¯\_(ツ)\_/¯
解决
Workaround
那我只能先把字符串插值去掉以后再说啦。
真正的解决方法
大概是加入一个输出并转移到下一个可以匹配的最长输入的转换函数。
不过还没有实际写代码。
TODO: 能不能解决这个问题啊